Database Design Using Hash Indexes
Hi guys, this is alanturrr1703.
This is my first blog, and honestly, I don’t know what I’m doing. But I’ll be writing these just for fun; some blogs might actually have some good points that could be useful to someone, but honestly, these blogs are my notes about things that I’m interested in.
Why Do We Need Databases?
Let’s dive into database design using Hash Indexes.
Now, why do we really need databases? Why can’t we use something like programs everywhere? When we’re designing software and want to output something that is, more often than not, static—say, user data—this type of problem, which is quite common, creates the need for a database. This data has to be stored permanently, so it can’t be kept in RAM. It also needs features like preventing redundant computation, ensuring simple data recovery, and so on.
I feel like if you’re reading my blog, you’ve already done some diligent work to understand these basic concepts.
What is Hashing and How Can It Be Used to Create Databases?
Now, let’s address the elephant in the room.
What is hashing, and how can it be used to create databases? Well, let’s get to the real stuff—though, for this blog, a deep explanation isn’t required. Hashing is like a secret formula applied to a number that gives the data an ID, functioning somewhat like encryption-decryption. If someone knows the hashing formula, or for those familiar with mathematics, the hashing function, they can decrypt the data.
However, we apply the hashing function not for data security but for fast data access.
Let’s see this with an example:
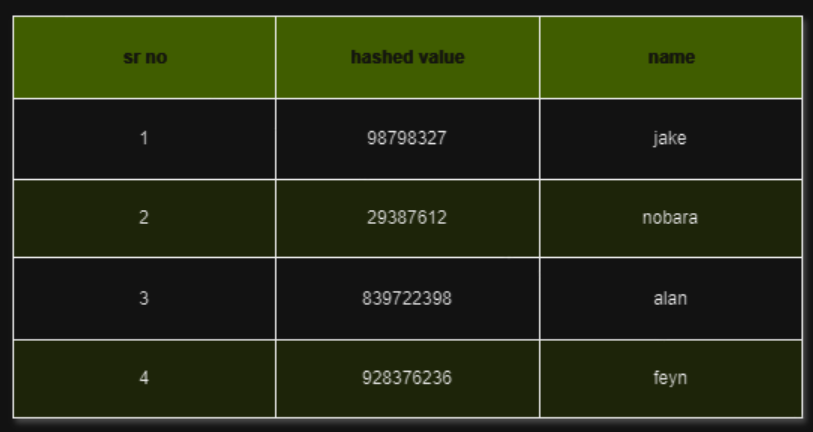
Fetching data for many users is simple with hashing.
For example, there’s this h(x), the hashing function. Whatever it may be, when you input 1 into the function, it will always output 98798327. And we know that in the hard drive, data related to Jake is stored at that location. But this might not be the case when using searching algorithms like binary search or linear search.
This may require O(N) space, but so does storing the data for searching. The cool part is that the time complexity of this algorithm is O(1). While writing a large amount of data can take time—O(N) with computation—the main issue here is the collision of data, where two hash functions produce the same output, like:
h(5) = 12345678h(10) = 12345678
which is the same.
In such cases, collision resolution algorithms are used, which may increase the writing complexity to O(N).
Using this hashing, we can design a database that works efficiently with hash indexes.
Downsides of Hashing
Now, let’s understand the downsides.
- Hashing happens in RAM; reading and writing involve RAM.
- RAM is costly.
- RAM isn’t reliable for storing permanent data.
- In case of a system failure, some data might be lost.
- If you didn’t get it from the above explanation, here’s a more in-depth one—just for you. 😘😘
You might be thinking, why not store the hash function in hard disk memory itself? Well, you’re not special; finding the data would be tough.
Now you might think we could store it in a way that makes it very accessible. Alright, you’re getting somewhere, but you’re still not a genius. This has been done using a Write-Ahead Log, which is like data you’ll likely need next, read and preloaded into the system when restarting. But even this can be optimized.
So yeah, that’s a summary of how this works.
Enjoy! Do whatever you want with this information.
I’ll be back with two more ways to design a database.
HEHE. 😁😁😁😁